EDIT: 11/18/2021 – With a death total rounding up to 1M, the true IFR in the US is probably around or over 0.5%, beyond my worst case estimates here. My model was a better predictive fit for places like Iceland – and I oversampled from such places and failed to predict the high mortality rates in certain demographics. (The striking geographic & demographic population differences in mortality probably stem more to differences in vitamin D and genetics rather than public policy.)
Covid-19 is either the greatest viral pandemic since the Spanish Flu of 1918 or it’s the greatest viral memetic hysteria since .. forever? The Coronavirus media/news domination is completely unprecedented – but is it justified?
For most people this question is obvious – as surely the vast scale of ceaseless media coverage, conversation, city lockdowns, market crashes, and upcoming bailouts is in and of itself strong evidence for the once-in-a-generation level threat of this new virus; not unlike how the vast billions of daily prayers to Allah ringing around the world is surely evidence of his ineffable existence. But no – from Allah to evolution, the quantity of believers is not evidence for the belief.
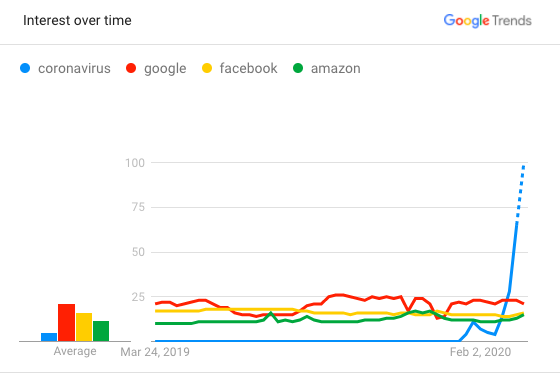
“Coronavirus” has recently become the #1 google search term, beating even “facebook”, “amazon”, and “google” itself. Meanwhile a google search of “coronavirus vs the flu” results in this knowledge-graph excerpt:
Globally, about 3.4% of reported COVID-19 cases have died. By comparison, seasonal flu generally kills far fewer than 1% of those infected.
Which is from this transcript of a press briefing by the WHO Director-General (Tedros Adhanom Ghebreyesus) on 3/3/2020. This sentence is strange in that Ghebreyesus was careful to use the word ‘reported COVID-19 cases’, but then compared that COVID-19 case fatality rate (CFR) to the estimated infection fatality rate (IFR) for flu of ‘far fewer than 1%’. What he doesn’t tell you is that the CFR of seasonal influenza is actually over 1%, but the estimated true IFR is about two orders of magnitude lower (as only a small fraction of infections are tested and reported as confirmed cases). If there was a live tally of the current Influenza season in the US, it would currently list ~23,000 deaths and 272,593 cases, for a CFR of ~8%.
The second google result links to a reasonable comparison article on medicalnewstoday.com which cites a situation report from the WHO, which states:
Mortality for COVID-19 appears higher than for influenza, especially seasonal influenza. While the true mortality of COVID-19 will take some time to fully understand, the data we have so far indicate that the crude mortality ratio (the number of reported deaths divided by the reported cases) is between 3-4%, the infection mortality rate (the number of reported deaths divided by the number of infections) will be lower. For seasonal influenza, mortality is usually well below 0.1%. However, mortality is to a large extent determined by access to and quality of health care.
This statement is mostly more accurate and careful – it more clearly differentiates crude case mortality from infection mortality, and notes that the true infection mortality will be lower (however, according to CDC estimates seasonal flu IFR is not ‘well below’ 0.1%, rather it averages ~0.1%). So where is everyone getting the idea that covid-19 is much more lethal than the flu?
Apparently – according to it’s own author – a blog post called “Coronavirus: Why You Must Act Now” has gone viral, receiving over 40 million views. It’s a long form post with tons of pretty graphs. Unfortunately it’s also quite fast and loose with the facts:
The World Health Organization (WHO) quotes 3.4% as the fatality rate (% people who contract the coronavirus and then die). This number is out of context so let me explain it. . .. The two ways you can calculate the fatality rate is Deaths/Total Cases and Death/Closed Cases.
No, the WHO did not quote 3.4% as the true fatality rate, and no that is not how any competent epidemiologist would estimate the true fatality rate, and importantly – that is not how the off-cited and compared 0.1% influenza fatality rate was estimated.
How Not to Sample
There is an old moral about sampling that is especially relevant here: if you are trying to estimate the number of various fish species in a lake, pay careful attention to your lines and nets.
For the following discussion, let’s categorize viral respiratory illness into 5 categories:
- 0: uninfected
- 1: infected, but asymptomatic or very mild symptoms
- 2: moderate symptoms – may contact doctor
- 3: serious symptoms, hospitalization
- 4: severe/critical, ICU
- 5: death
If covid-19 tests are only performed post-mortem (sampling only at 5), then the #confirmed_cases = #confirmed_deaths, and case fatality rate (CFR) is 100%. If covid19 tests are only on ICU patients, then CFR ~ N(5)/N(4+) , the death rate in ICU. If covid19 tests are only on hospital admissions, then CFR ~ N(5)/N(3+), and so on. The ideal scenario of course is to test everyone – only then will confirmed case mortality equal true infective mortality, N(5)/N(1+).
The symptoms of covid-19 are nearly indistinguishable to those of ILI (Influenza-like-Illness), which acknowledges that many diverse viral or non-viral conditions can cause a similar flu-like pattern of symptoms. Thus covid-19 confirmation relies on a PCR test.
When testing capacity is limited, it makes some sense to allocate those limited testkits to more severe patients. Testing has been limited in the US and Italy – which suggests very little testing of patients at illness levels 1 and 2. In countries where testing is more widespread, such as Germany, Iceland, Norway and a few others, the crude case mortality is roughly an order of magnitude lower, but even in those countries they are probably testing only a fraction of patients at level 2 and a tiny fraction of those at level 1 (who by and large are not motivated to seek medical care).
That Other Pandemic
In 2009 there was an influzena pandemic caused by a novel H1N1 influenza virus (a descendant variant of the virus that caused the 1918 flu pandemic). According to CDC statistics, by the end of the pandemic there were 43,677 confirmed cases and 302 deaths in the US ( a crude CFR of 0.7%) – compare to current (3/24/2020) US stats of 50,860 covid-19 confirmed cases and 653 deaths. From the abstract:
Through July 2009, a total of 43,677 laboratory-confirmed cases of influenza A pandemic (H1N1) 2009 were reported in the United States, which is likely a substantial underestimate of the true number. Correcting for under-ascertainment using a multiplier model, we estimate that 1.8 million–5.7 million cases occurred, including 9,000–21,000 hospitalizations.
Later in the report they also correct for death under-ascertainment to give a median estimate of 800 deaths. So their median predicted IFR is ~0.02%, which is 35 times lower than the CFR (and 5 times lower than the estimated mortality of typical seasonal flu).
What’s perhaps more interesting is how (retrospectively) terrible early published mortality estimates were in hindsight: (emphasis mine)
We included 77 estimates of the case fatality risk from 50 published studies, about one-third of which were published within the first 9 months of the pandemic. We identified very substantial heterogeneity in published estimates, ranging from less than 1 to more than 10,000 deaths per 100,000 cases or infections. The choice of case definition in the denominator accounted for substantial heterogeneity, with the higher estimates based on laboratory-confirmed cases (point estimates= 0–13,500 per 100,000 cases) compared with symptomatic cases (point estimates= 0–1,200 per 100,000 cases) or infections (point estimates=1–10 per 100,000 infections).
So what about that 0.1% flu mortality statistic?
The off-quoted 0.1% flu mortality probably comes from the CDC, using a predictive model described abstractly here. In particular, they estimate N(1+), the total number of influenza infections, from the number of hospitalizations N(3+) and a sampling driven estimate of the true hospitalization ratio N(1+)/N(3+):
The numbers of influenza illnesses were estimated from hospitalizations based on how many illnesses there are for every hospitalization, which was measured previously (5).
Some people with influenza will seek medical care, while others will not. CDC estimates the number of people who sought medical care for influenza using data from the 2010 Behavioral Risk Factor Surveillance Survey, which asked people whether they did or did not seek medical care for an influenza-like illness in the prior influenza season (6).
Hopefully they will eventually apply the same models to covid-19 so we can at least have apples-to-apples comparisons, although it looks like their influenza model estimates also leave much to be desired. In the meantime there are a number of other interesting datasets we can look at.
A Tale of Two Theories:
Let’s compare two plausible theories for covid19 mortality:
- Mainstream: Covid19 is about 10x worse/lethal than seasonal influenza
- Contrarian: Covid19 is surprisingly similar to seasonal influenza
First, let us more carefully define what “10x worse/lethal” means, roughly. Recall that the true infective mortality is the unknown difficult to measure ratio N(5)/N(1+) – the number of deaths due to infection over the actual number infected. That ratio is useful for doing evil things such as estimating the future death toll of a pandemic by multiplying by the attack rate N(1+)/N – the estimated fraction infected.
We can factor out the death rate as the product of the fraction progressing to more severe disease at each step:
N(2+)/N(1+) * N(3+)/N(2+) * N(4+)/N(3+) * N(5)/N(4+)
So there are numerous means by which covid19 could have a 10x higher overall mortality than influenza. For example it could be that only N(5)/N(4+) is 10x higher (the fatality rate given ICU admission), if for example covid19 is much harder to treat in ICU. Or it could be that all the difference is concentrated in N(2+)/N(1+): that covid19 has a very low ratio of mild or asymptomatic patients. A priori, based on cross comparisons of other respiratory viruses (ie cold vs flu), it seems more likely that the any difference between covid19 and influenza is probably spread out across severity (the lower mortality of the common cold vs flu is spread out across a lower rate of serious vs mild illness, lower rate of hospitalization, lower rate of ICU, lower rate of death, etc).
Here is a collection of estimates for various hospitalization, ICU, and death ratios for influenza and covid19 ( N(C) denotes the number of lab confirmed cases ) :
- Influenza N(5)/N(3) ~ 0.07 (CDC 2018-2019 US flu season estimates)
- COVID-19 N(5)/N(3) ~ 0.08-0.10 (CDC COVID-19 weekly report table 1)
- Influenza N(4)/N(3) ~ 0.23 (Beumer et al Netherlands hospital study)
- COVID-19 N(4)/N(3) ~ 0.23-0.36 (CDC)
- Influenza N(5)/N(4) ~ 0.38 (Beumer et al)
- COVID-19 N(5)/N(4) ~ 0.29-0.36 (CDC)
- 2009 H1N1 N(3)/N(C) ~ 0.11 (Reed et al CDC dispatch)
- 2019 Flu N(3)/N(C) ~ 0.07 (CDC Influenza Surveillance Report)
- COVID-19 N(3)/N(C) ~ 0.20 (CDC)
Note that the influenza data for hospitalization outcomes comes from two very different sources (CDC estimates based on US surveillance vs data from a single large hospital in the Netherlands), but they agree fairly closely: about a quarter of influenza hospitalizations go to ICU, a bit over a third of ICU patients die, and thus about one in 12 influenza hospitalizations lead to deaths. The COVID-19 ratios have somewhat larger error bounds at this point but are basically indistinguishable.
The N(3)/N(C) ratio (fraction of confirmed cases that are hospitalized) appears to be roughly ~2x higher for covid-19 compared to influenza, which could be caused by:
- Greater actual disease severity of covid-19
- Greater perceived disease severity of covid-19
- Selection bias differences due to increased testing for influenza (over 1 million influenza tests in the US this season vs about 100k covid-19 tests)
So to recap, covid-19 is similar to influenza in terms of:
- The fraction of hospitalizations that go to ICU
- The mortality in ICU
- The overall mortality given hospitalization
- The overall mortality of confirmed cases
The mainstream theory (10X higher mortality than flu) is only compatible with this evidence if influenza and covid-19 differ substantially in terms of the ratio N(1+)/N(C) – that is the ratio of true total infections to laboratory confirmed cases, which seems especially unlikely in the US given it’s botched testing rollout with covid-19 testing well behind influenza testing. If covid-19 is overall more severe on average, that could plausibly lead to a lower N(1+)/N(C) ratio, but it seems unlikely that the increase in severity is all conveniently concentrated in the one variable that is difficult to measure.
The Diamond Princess

Sometime in late January covid-19 began to silently spread through the mostly elderly population onboard the Diamond Princess cruising off the coast of Japan. The outbreak was not detected until a week or two later; a partial internal quarantine was unsuccessful. The data from this geriatric cruise ship provides a useful insight into covid-19 infection in an elderly population as most all 3,711 passengers and crew were eventually tested.
Now that it has been almost two months since the outbreak the outcome of most of these cases is known. However, worldometers is still reporting 15 patients in serious/critical state. I’ve pieced together the age of deaths from here and news reports, but there are 2 recent deaths reported from Japan of unknown age. Thus I’ve given an uncertainty range for the 2 actual deaths of unknown age and an estimate of potential future deaths based on the previously discussed ~30% death ratio for ICU patients. I pieced together flu age mortality from 2013-2014 flu season CDC data here and from livestats and provided 95% CI binomial predictions. The 2013 flu season was typical overall but somewhat higher (estimated) mortality in the elderly. The final column has predictions using covid-19 CDC case mortality.
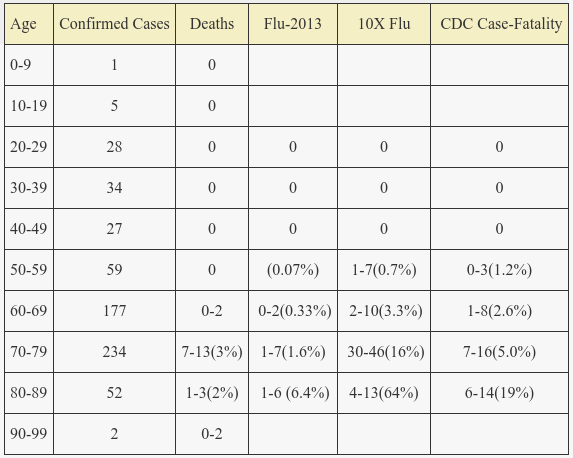
The observed actual death rates are rather obviously incompatible with the theory that covid-19 is 10x more lethal than influenza across all age brackets in this cohort.
The observed deaths is close to the Influenza-2013 predictions except for the 7 (or a few more) deaths in the 70-79 age group which is about ~2x higher than predicted. The CDC case mortality model predictions are much better than 10x flu, but are still a poor fit for the observed mortality. More concretely, the Influenza-2013 model has about a 100x higher bayesian posterior probability than the CDC case fatality model. The latter severely overpredicts mortality in all but the 70-79 age bracket.
One issue with the Diamond Princess data is that a cruise ship population has it’s own sampling selection bias. Of course this is obviously true here in terms of age, but there also could be bias in terms of overall health. People in the ICU probably aren’t going on cruises. On the other hand, cruises are not exactly the vacation of choice for fitness aficionados. It seems likely that this sampling bias mostly affects the tail of the age distribution (as the fraction of the population with severe chronic illness preventing a cruise increases sharply with age around life expectancy) and could explain the flatter observed age mortality curve and low deaths in the 80-89 age group.
One common response to the Diamond Princess data is that it represents best case mortality in uncrowded hospitals with first rate care. In actuality the Diamond Princess patients were treated in a number of countries, so the mortality data is in that sense representative of a mix of world hospital care – and hospitals are generally already often overcrowded. That being said, most of the reported deaths seem to be from Japan – make of that what you will.
But moreover the entire idea that massively overcrowded hospitals will lead to high mortality rests on the assumption that the attack rate and or hospitalization rate (and overall severity) of covid-19 is considerably higher than influenza. But the severity in terms of ICU and death rates per hospitalization are very similar, and the ratio of hospitalizations as a fraction of confirmed cases is only ~2x greater for covid-19 vs influenza data, as discussed earlier – well within the range of uncertainty.
My main takeaway points from the Diamond Princess data is that:
- The observed covid-19 mortality curve on this ship is similar to what we’d expect from unusually bad seasonal influenza.
- The CDC case mortality curve probably overestimates mortality more in younger age groups (it is not age skewed enough). The true age skew rate seems very similar to seasonal influenza.
But What about Italy?

Several of the most virulent popular coronavirus memes circulating online all involve Italy: that Italy’s hospitals have been pushed to the breaking point, or that morgues are overflowing. And yet, as of today the official covid-19 death count from Italy stands at 6,077 – which although certainly a terrible tragedy – is still probably less of an overall tragedy than the estimated few ten thousands who die from the flu in Italy every year. (Of course there is uncertainty in the total death counts from either virus and it’s a reasonable bet that covid-19 will kill more than influenza this year in Italy).
Nonetheless, I find this tidbit fact from a random article especially ironic:
They average age of those who have died from COVID-19 in Italy is 80.3 years old, and only 25.8% are women.
Goggle says life expectancy in Italy is about 82.5 years overall, and only 80.5 for men. So on average covid-19 is killing people a few months early?
The only stats I can find for the average age of death of flu patients is for the 2009 H1N1 flu from the CDC, which lists an average age of death of 40.
Hospital overcrowding is hardly some new problem – influenza also causes that. It’s just newsworthy now, when associated with coronavirus. And do you really think that the Morgue capacity issues of a town or two in Italy would be viral hot news if it wasn’t associated with coronavirus? At any given time a good fraction of hospitals are overcrowded as are some morgues. In any country size dataset of towns and their mortality rates you will always find a few exemplars currently experiencing unusually high death rates. None of this requires any explanation.
Concerning Italy’s overall unusually high covid-19 case mortality – is that mostly a sampling artifact caused by testing only serious cases, or does the same disease actually have a 30x higher fatality rate in Italy than in Germany?
One way to test this is by looking at the age structure of Italy’s coronavirus cases and comparing that to the age structure of the population at large. With tens of thousands of confirmed cases from all over Italy it is likely that the attack rate is now relatively uniform – it has spread out and is infecting people of all ages (early in an epidemic the attack rate may be biased based on some initial cluster, as still is probably the case in South Korea where the outbreak began in a bizarre cult with a younger median age).
Let’s initially assume a uniform attack rate N(1+)/N(0+) across age – that the true fraction of the population infected does not depend much on age. We can then compare the age distribution of Italy’s confirmed cases to the age distribution of Italy’s population at large to derive an estimate of case under-ascertainment. The idea is that as infection severity increases with age and detection probability increases with severity, the fraction of actual cases detected will increase with age and peak in the elderly. This is a good fit for the data from Italy, where the distribution of observed covid-19 cases is extremely age skewed.
The number of confirmed cases is roughly the probability of testing given infection times the probability of infection times the population size (the net effect of false positive/negative test probabilities are small enough to ignore here):
N(C) = p(C|I)*p(I)*N
From the Diamond Princess data we know that even for the elderly population the fraction of infected who are asymptomatic or mild is probably higher than 50%, so we can estimate that p(C|I) is at most 0.5 for any age group (and would only be that high if everyone with symptoms was tested). Substituting that into the equation above for the eldest 80+ group results in an estimate for p(I) of 0.005 and the following solutions for the rest of the p(C|I) values by age:
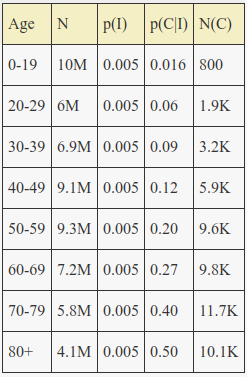
This suggests that the actual total number infected in Italy was at least 0.5% of the population or around ~300,000 true cases as of a week ago or so assuming an average latency between infection and lab confirmation of one week.
Almost all of Italy’s 5K deaths are in the 70-79 and 80+ age brackets, for a confirmed case mortality in those ages of roughly 25%. This is about 10x higher than observed on the Diamond Princess. Thus a more reasonable estimate for the peak value of p(C|I) is 0.25. Even for the elderly, roughly half of cases are asymptomatic/mild, and half of the remaining are only moderate and do not seek medical care and are not tested. We can also apply a non-uniform attack rate that decreases with age, due to the effects of school transmission and decreasing general infection prone social activity with age.
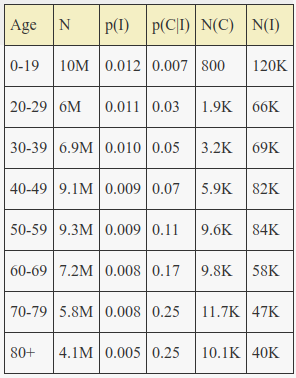
With an attack rate varying by about 2.5x across age and a max p(C|I) of 0.25, Italy’s total actual infection count is ~566,000 as of a week or so ago – or almost 1% of the population. This is still assuming about double the age 70+ mortality rates observed on the Diamond Princess, so the actual number of cases could be over a million.
Another serious potential confounder is overcounting deaths at the coroner (which I found from this rather good post from the Center for Evidence Based Medicine. Incidentally, the author also reaches my same conclusion about covid-19 IFR ~ influenza IFR):
In the article, Professor Walter Ricciardi, Scientific Adviser to, Italy’s Minister of Health, reports, “On re-evaluation by the National Institute of Health, only 12 per cent of death certificates have shown a direct causality from coronavirus, while 88 per cent of patients who have died have at least one pre-morbidity – many had two or three.”
So some difficult-to-estimate chunk of Italy’s death count could be death with covid-19 rather than death from covid-19 (and this also could explain why the average age of covid-19 deaths in Italy is so close to life expectancy).
United States Age Projection
Applying the same last model parameters to the United States general age structure and confirmed covid-19 case age structure results in the following:
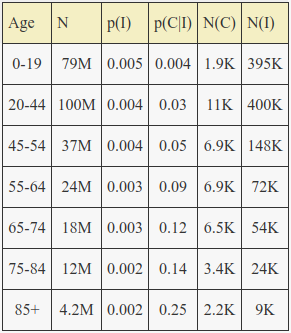
The estimated total number of infections in the US as of a week or so ago is thus ~ 1.1 million, with an estimated overall mortality in the range of 0.1%, similar to the flu. The average mortality in Italy probably is higher partly just because of their age skew. The US has a much larger fraction of population under age 60 with very low mortality.
Assuming that at most 1 in 4 true infections are detected in the elderly, we see that only about 1 in 30 infections are detected in those ages 20-44 and only a tiny fraction of actual infections are detected in children and teens.
Remember the only key assumptions made in this model are:
- That the attack rate decreases linearly with age by a factor of about 2x from youngest to oldest cohorts, similar to other respiratory viruses (due to behavioral risk differences)
- That the maximum value of p(C|I) in any age cohort – the maximum fraction of actual infections that are tested and counted, is 0.25.
The first assumption only makes a difference of roughly 2x or so compared to a flat attack rate.
In summary – the age structure of lab confirmed covid-19 cases (the only cases we observe) is highly skewed towards older ages when compared to the population age structure in Italy and the US. This is most likely due to a sampling selection bias towards detecting severe cases and missing mild and asymptomatic cases – very similar to the well understood selection bias issues for influenza. We can correct for this bias and estimate that the true infection count is roughly 20x higher than confirmed infection count in the US, and about 10x higher than confirmed infection count in Italy.
The Worst Case
In the worst case, the US infection count could scale up by about a factor of 200x from where it was a week or so ago. With the same age dependent attack rate that would entail everyone under age 20 in the US becoming infected along with 40% of those age 75 and over. Assuming the mortality rates remains the same, the death count would also scale up by a factor of 200x, perhaps approaching 200K. This is about 4x the estimated death toll of the seasonal flu in the US. Yes there is risk the mortality rates could increase if hospitals run out of respirators, but under duress the US can be quite good at solving those types of rapid manufacturing and logistics problems.
However the pessimistic scenario of very high infection rates seems quite unlikely, given:
- The infection rate of only ~20% on the cramped environment of the Diamond Princess cruise ship
- The current unprecedented experiment in isolation, sterilization, and quarantine.
A potential critique of the model in the previous section is that we don’t know the true attack rate and it may be different from other known respiratory viruses. However, this doesn’t actually matter in terms of total death count. We can factor out p(I) as p(I|E)p(E) – the probability of infection is the probability of infection given exposure times the probability of exposure. A biological mechanism which causes p(I|E) to be very low for the young (to explain their low observed case probability) would result in lower total infection counts and thus higher mortality rates, but it wouldn’t change the maximum total death count – as that is computed by simply scaling up maximum p(E) to 1. So you could replace I with E in the previous model and nothing would change. In other words, that same biological mechanism resulting in lower p(I|E) would also just reduce total infections by the same ratio it increased infected mortality rate, without affecting total deaths.
The Bad News: Current confirmed case count totals (~43K as of today) are a window into the past, as there is about 5 days of incubation period and then at least a few days delay for testing for those lucky enough to get a test. So if the actual infection count was around 1 million a week ago, there could already be more than 5 million infected today, assuming the 30% daily growth trend has continued. So the quarantine was probably too late.
True Costs
Combining estimates for total death count, years of counterfactual life expectancy lost, and about $100k/year for the value of a year of human life from economists we can estimate the total economic damage.
A couple examples using a range of parameter estimates:
- 50k deaths * 1yr life lost * $100k/yr = $5 billion
- 200k deaths * 3yr life lost * $100k/yr = $60 billion
- 500k deaths * 10yr life lost * $100k/yr = $500 billion
In terms of economic damage, the current stock market collapse has erased about 30% of the previous value of ~$80 trillion, for perhaps $23 trillion in economic ‘damage’. I put damage in quotes because trade values can change quickly with expectations, and there is no actual loss in output or capability as of yet. In terms of GDP, some economists give estimates in the range of a 10% to 20% contraction, or $2 to $4 trillion of direct output loss for the US alone.
Although imprecise, these estimates suggest that our current mass quarantine response is expected to do one to two orders of magnitude more economic utility damage than even worst case direct viral deaths.
One silver lining is that much of this economic damage lies in the future predicted. It can still be avoided when/if it becomes more clear that the death toll will be much lower than original worst case forecasts suggested.







